Paper Reading task
BERTscore: Evaluating text generation with Bert
By- Dikshant
Index
BERT is a evolution over the transformer based architectures that uses attention-mechanism i.e gives contextual information for every word. Since Transformers usually aren't bidirectional. It's hard for them to guess the acutal context of the word in a sentence whereas BERT is a bidirectional model => can contextualize the word more effeciently.
Why BERTscore ?
BERTScore was developed to address the limitations of traditional evaluation metrics like BLEU and ROUGE in the field of Natural Language Processing (NLP). These traditional metrics, which are based on n-gram matching, often fail to capture the semantic similarity between texts, especially when the texts use different but semantically similar phrases.
One of the key features of BERTScore is its ability to provide robust paraphrase matching. It leverages the power of BERT’s contextual embeddings to compute similarity scores between tokens in a candidate sentence and a reference sentence. This allows BERTScore to effectively match paraphrases and evaluate the quality of generated text, such as in machine translation or text summarization.
SUMMary
The paper discusses about evaluating text generation with the help of BERT.
Suppose we generated text using some BERT model then the similarity between generated text and actual text is the BERTscore.
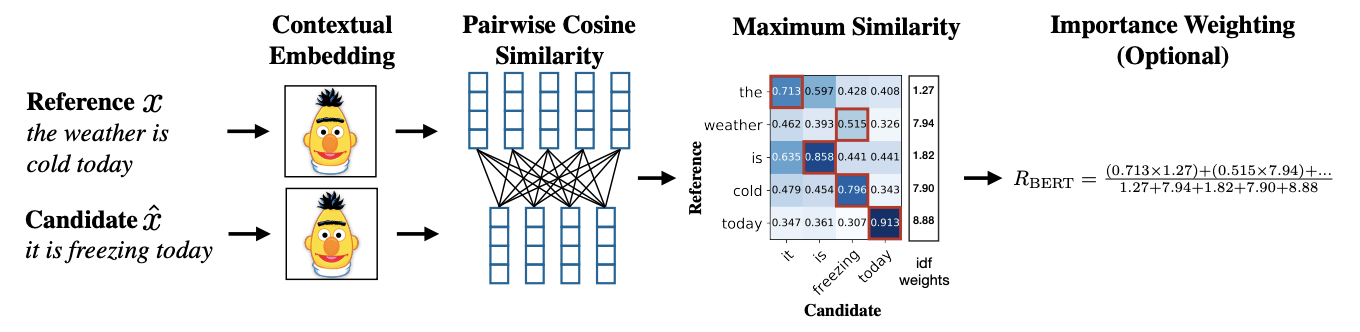
In the CNN diag. we see that we pass Reference X and Candidate X̂ through pre-trained bert model that generates Contextual Embeddings.
The contextual embedding is then checked for similarity for each of the words from reference to each of the word in candidate set.
Now we sum max. similarity for each of the words from reference to the candidate. Then Normalize it.
Similar stuff was done from candidate to reference context by normalizing by the total no. of words we have in candidate we call it Precision.
Then we can have F-score which H.M. of precision and recall.
- Capturing Distant Dependencies: BERTscore's contextual embeddings are trained to recognize order and deal with distant dependencies present in the text where as previous models were not that efficient when there were changes in semantic order.
- Task-Independent Evaluation: BERTScore is a versatile evaluation metric that can be used for various text generation tasks.
- Accurate: Using precision and recall values BERTscore make text similarity more accurate and balanced.
- BIRTscore supports importance weighting which we estimate with simple corpus statistics.
ADVANTAGES
- Slow: Since the contextual embedding set is passed for consine similarity where each of the words from reference to each of the word in candidate set. i.e n^2 computations.
i.e not at all good for semantic similarity.
- If the candidate text is lexically or stylistically similar to reference text. Then it might lead to overestimation quality of generated text.
- Since it's based on BERT so it contextual embedding might not be correct if a non grammatical data-set is trained on grammatical data.
Disadvantages
- Since the model is very slow so they can use Simese Neural Network to improve the speed.
- Also computing pairwise comparision tokens in the reference and candidate sentences is a computational heavy task. So we can remove less promising pairs early in the process and prevent the task of computing their cosine-similarity.